 作者:尼尔·波尔赫姆斯博士
作者:尼尔·波尔赫姆斯博士
Statgraphics Centurion第20版在其预测分析方法集合中增加了10个新的监督机器学习(ML)程序。监督机器学习程序是人工智能算法,它使用一组具有已知结果的数据来预测结果尚未确定的情况。这些算法适合训练集,并使用单独测试集中的一组已知案例或使用在训练集上执行的交叉验证进行调整。ML程序处理2种类型的结果:分类结果,其中一个或多个输入特征用于对每个案例进行分类,或者定量结果,其中输入特征用于预测结果变量的值。
版本20还包含一个监督机器学习向导,可以轻松地将多个方法应用于同一个数据集。该向导还允许组合多个方法以创建单个集成预测。
示例
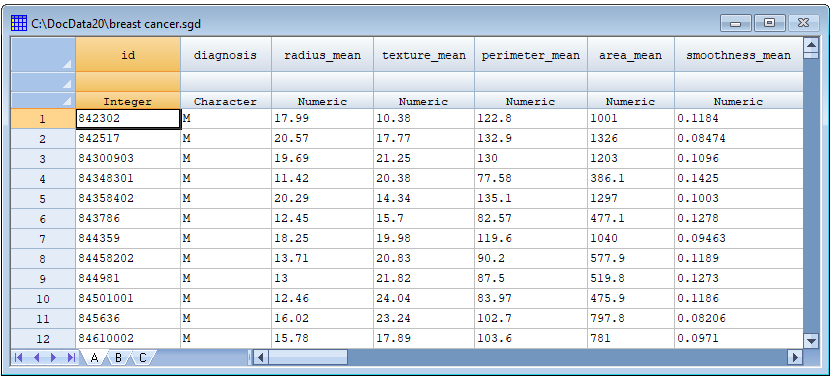
加州大学欧文分校机器学习存储库(https://archive.ics.uci.edu/)包含威斯康星大学收集的数据集,其中包含在女性乳房中发现的569个肿块的信息。每个肿块通过使用细针吸出物(FNA)拍摄的数字化图像中对细胞核进行30次测量来表征。每个肿块后来被确定为恶性或良性。目标是根据30次测量将未知肿块分类为恶性或良性。文件的一部分如下所示:
监督机器学习向导
在版本20中,用户可以选择单独或在向导的控制下运行10个新的机器学习过程。该向导有几个优点:
1.无论使用多少种方法,输入数据都只需要指定一次。
2.多个程序的预测能力以表格和图形格式并排比较。
3.可以组合多种方法来产生单一的集合预测,这可能比单独使用单一方法要好。
要运行向导,用户转到学习菜单并选择向导(Python)。向导调用的每个过程都包含在名为scikit-learn(https://scikit-learn.org/stable/index.html)的Python库中。向导会打开一个带有工具栏的窗口,引导用户完成模型拟合和预测的5个步骤:
第1步:选择输出和功能
每个ML过程都需要一个输出变量和一个或多个输入变量,其中包含可用于预测结果的特征:
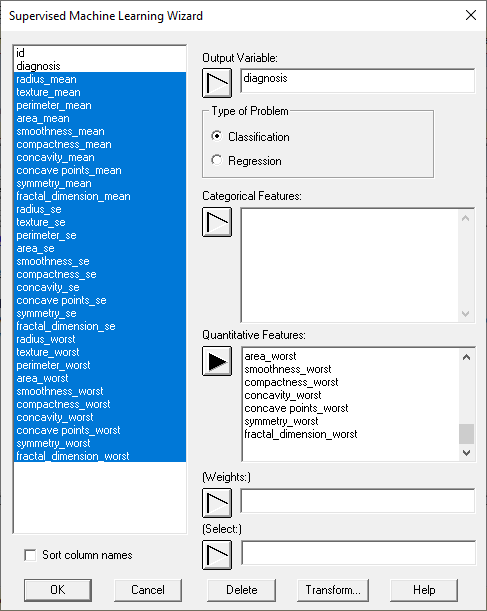
用户还指定这是一个分类问题还是回归问题。如果某些情况比其他情况赋予更多的权重,则可以指定权重。当数据文件的每一行代表一组主题而不是单个主题时,这尤其有用。在这种情况下,权重通常设置为等于组大小。
第2步:定义训练和测试集
在监督机器学习中,数据文件中的案例通常分为3组:
集合#1:具有已知结果的训练集,用于训练或拟合算法。
集合#2:具有已知结果但在训练期间未使用的测试集。对测试集进行的预测用于确定方法的性能并在不同方法之间进行选择。
集合#3:具有未知结果的预测集,一旦方法经过训练,就会对其进行预测。
该向导显示以下对话框以帮助用户定义这些集合:
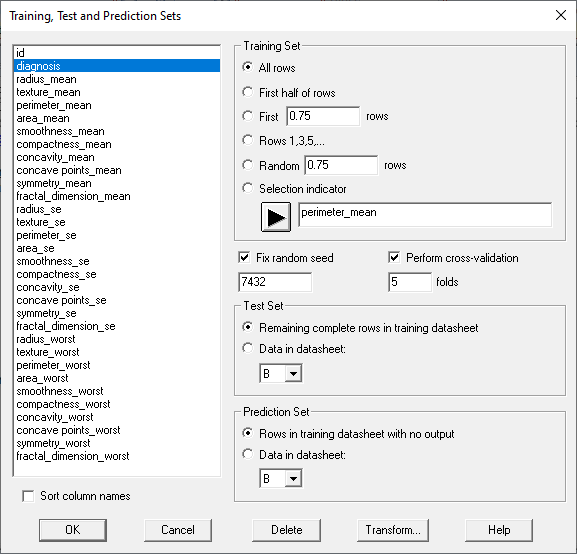
由于样本量相对较小,上面的对话框将所有行放入训练集中。
第3步:设置选项
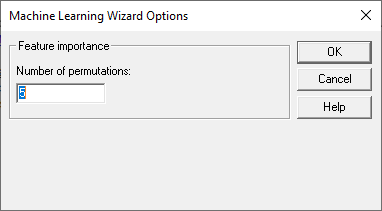
当算法使用大量特征时,通常情况下,某些特征在预测结果时比其他特征更重要。为了确定哪些特征最重要,机器学习算法通常通过随机排列选定特征列中的条目来检查每个特征的重要性,并评估预测比使用特征值的真实序列差多少。特征越重要,当该列中的值按正确顺序排列时,方法的性能与随机洗牌时的性能之间的差异就越大。
步骤3的对话框指定每个特征列应该置换多少次:
第4步:拟合模型
Step 4按钮用于训练一种或多种算法。它显示以下对话框:
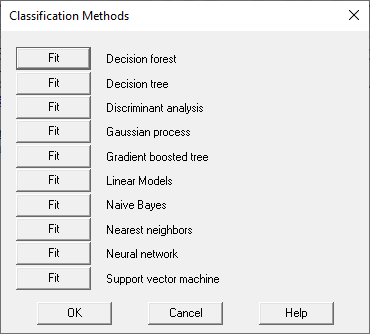
每次按下Fit按钮时,都会调用指定的过程。请注意,可以多次选择相同的过程。因为用户可能希望尝试使用不同的参数设置运行相同的过程。
例如,假设选择了最近的邻居按钮。在训练模型之前,将显示该过程的分析选项对话框:
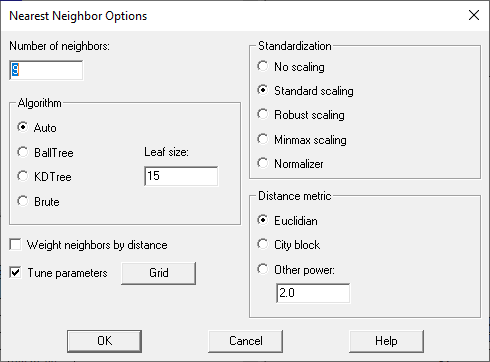
从概念上讲,最近邻过程通过将其与特征变量空间中最接近未知情况的指定数量的训练情况(默认为5个)进行匹配来预测未知情况。用户有各种选择:
1.匹配每个案例的最近邻数。
2.用于查找最近邻的算法(在大型数据集中,尝试所有可能性非常耗时)。
3.在计算距离之前,通常具有不同单位的特征变量应该如何缩放。
4.距离应该如何计算。
5.在进行预测时,是否应该给最近的邻居更多的权重。
显然,可以选择许多参数组合。为了帮助用户找到好的参数值,每个分析选项对话框都有一个标记为Tune参数的复选框和一个标记为Grid的按钮。如果选中,算法将使用按下Grid按钮时显示的对话框指定的各种参数值组合进行训练:
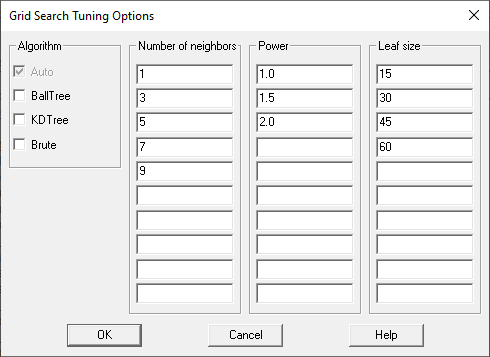
默认情况下,最近邻方法将被训练60次(1个算法具有5个邻居数,具有3个幂值和4个叶大小值)。在交叉验证期间给出最佳预测性能的组合将被选中。
用户还可以选择各种表格和图表来显示最近邻方法的结果:
按下OK时,将打开一个新窗口并显示结果:
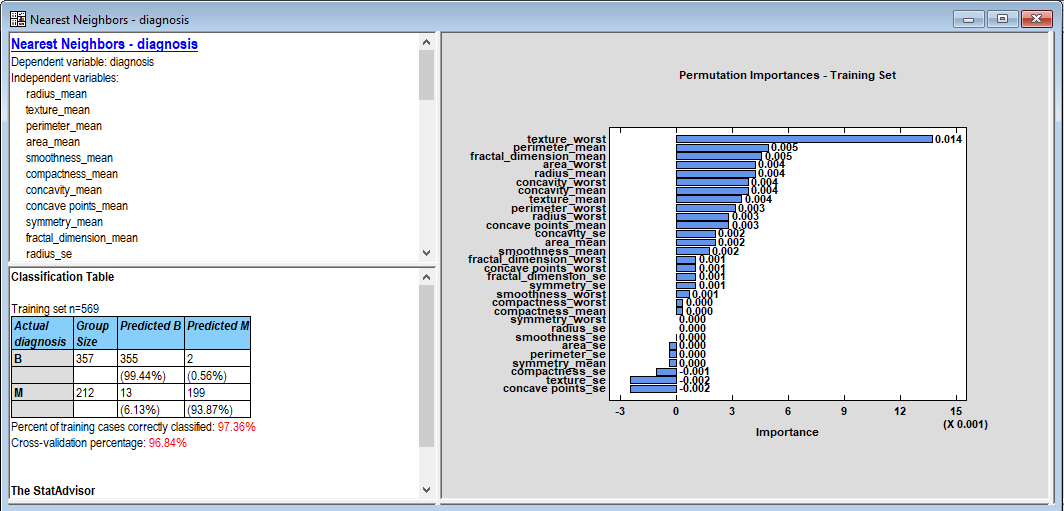
右侧窗格中的特征重要性图显示了按重要性降序绘制的30个特征。在这里,重要性是通过以正确的顺序对特征进行排序而不是以随机顺序对其进行排序而生成的正确预测比例的增加来衡量的。最重要的特征texture_worst在正确排序时会产生约1.4%的正确预测。
如果对每种方法重复步骤4按钮,向导将生成一个比较其性能的图表:
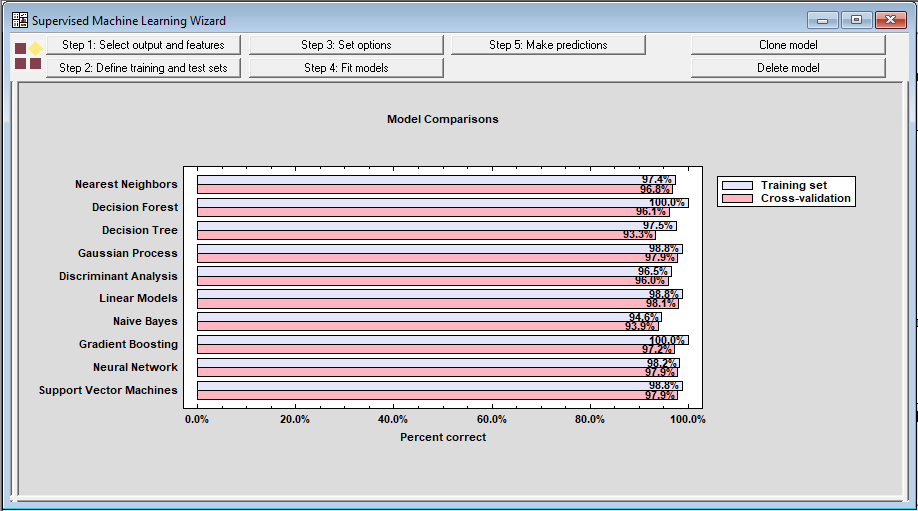
交叉验证期间表现最好的方法实际上是线性模型(在这种情况下是逻辑回归,因为结果是分类的)。在交叉验证期间,平均98.1%的时间是正确的。
第5步:做出预测
选择和调整一个或多个监督机器学习过程的目的通常是对结果未知的情况进行预测。例如,我在数据文件的底部添加了一个额外的行,其中我放置了每个特征的平均值,但将结果留空。没有结果的行会自动添加到预测集中。
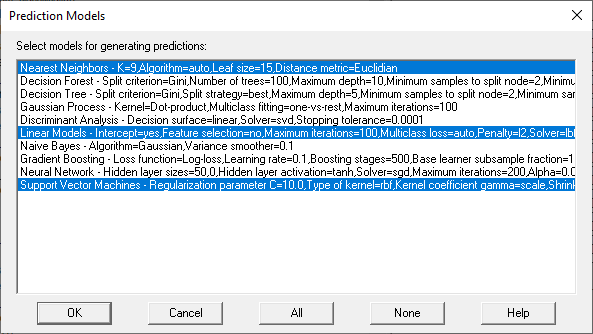
在此步骤中,向导首先显示已调整的所有方法的列表。
.
然后,用户选择一个或多个方法来预测未知情况。选择多个方法有时会很有帮助,这会创建称为集成预测的东西。如果选择了多个方法,向导将显示一个对话框,其中包含组合来自不同方法的预测的选项:
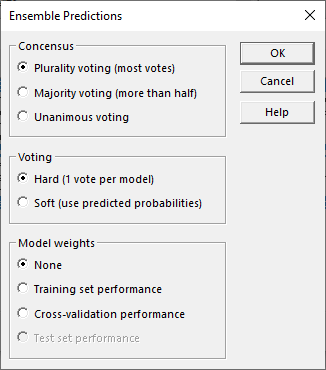
如果需要,性能更好的方法可以在确定最终预测时给予更多权重。投票也可以根据每个方法预测正确的估计概率进行组合。
当我给每个方法1票时,向导生成了以下输出:
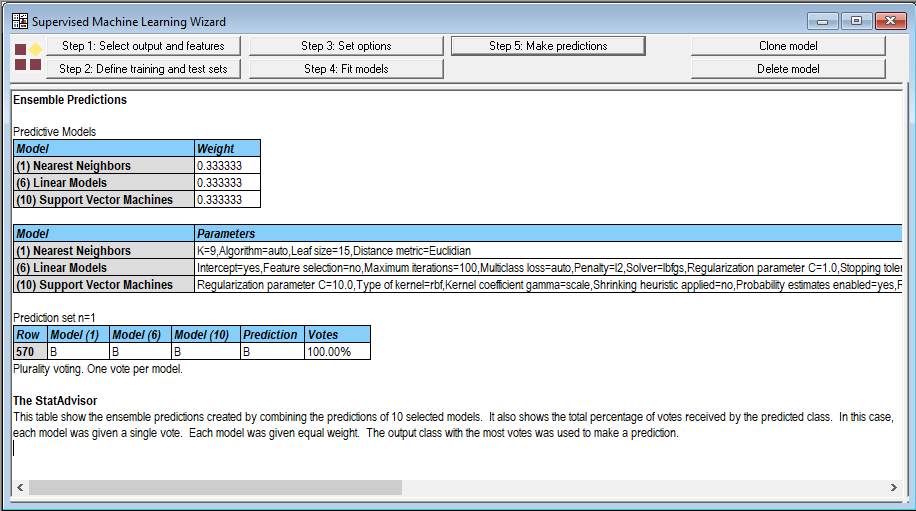
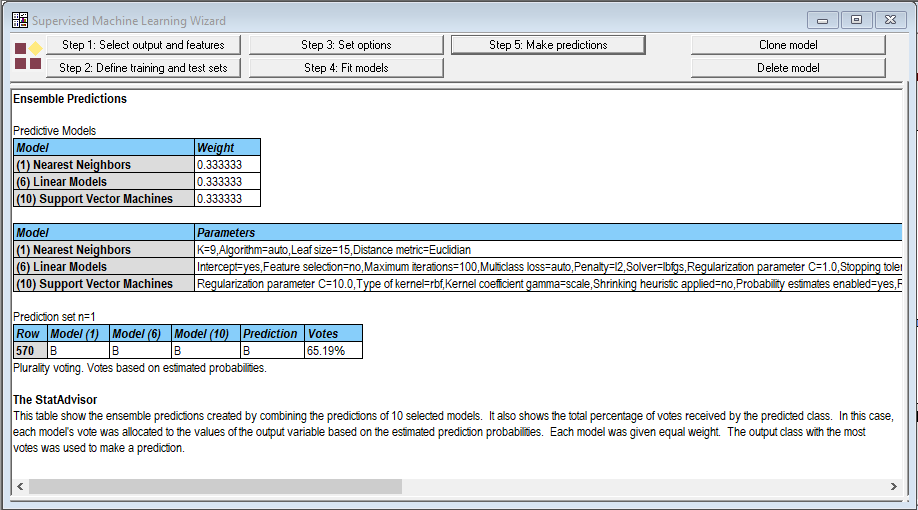
所有三种方法都预测质量将是良性的。但是当我选择使用预测概率进行投票时,结果并不那么令人鼓舞:
观察各个窗口,我注意到以下预测:
最近的邻居:

线性模型:

支持向量机:

质量是良性的概率平均值为0.6519,这是用来创造最终投票的。这不是一个你想拿生命打赌的结果。